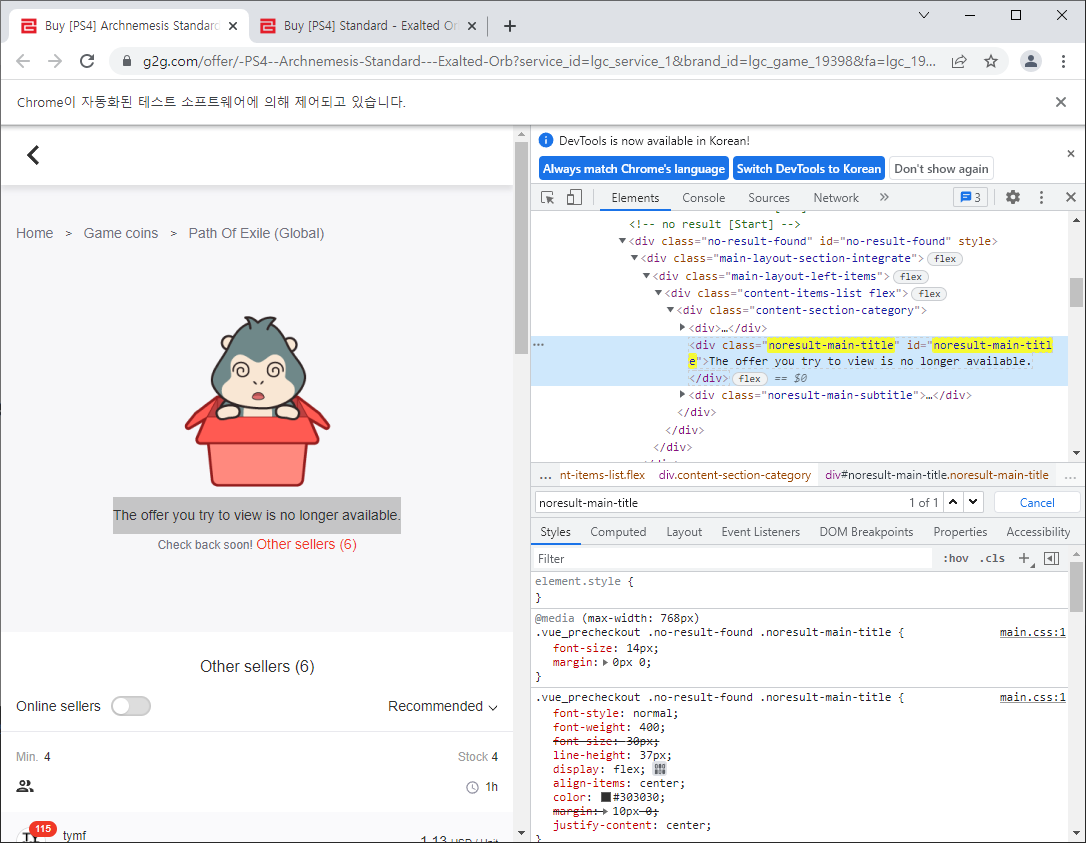
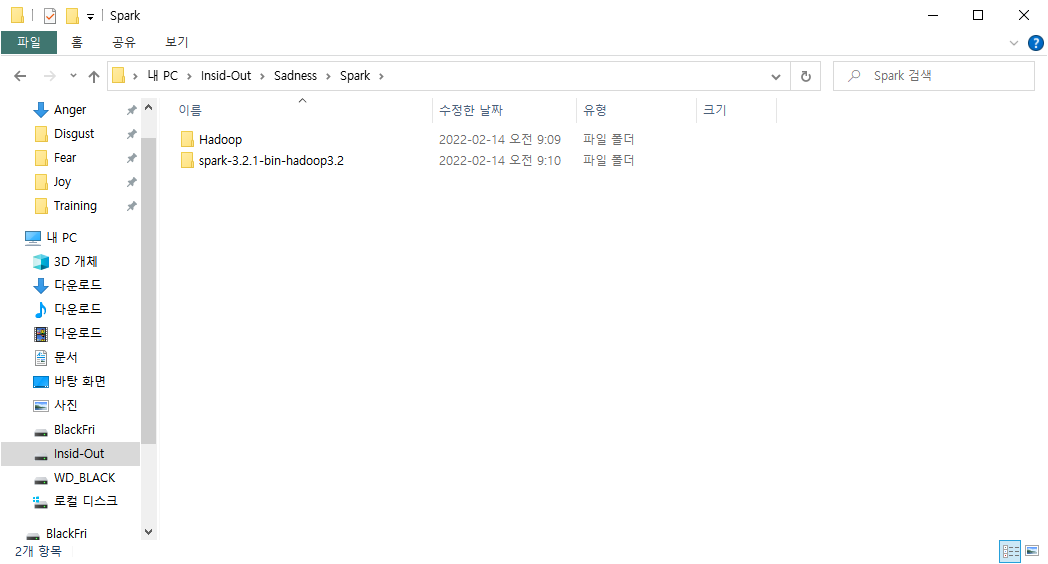
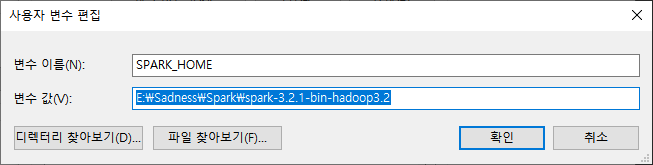
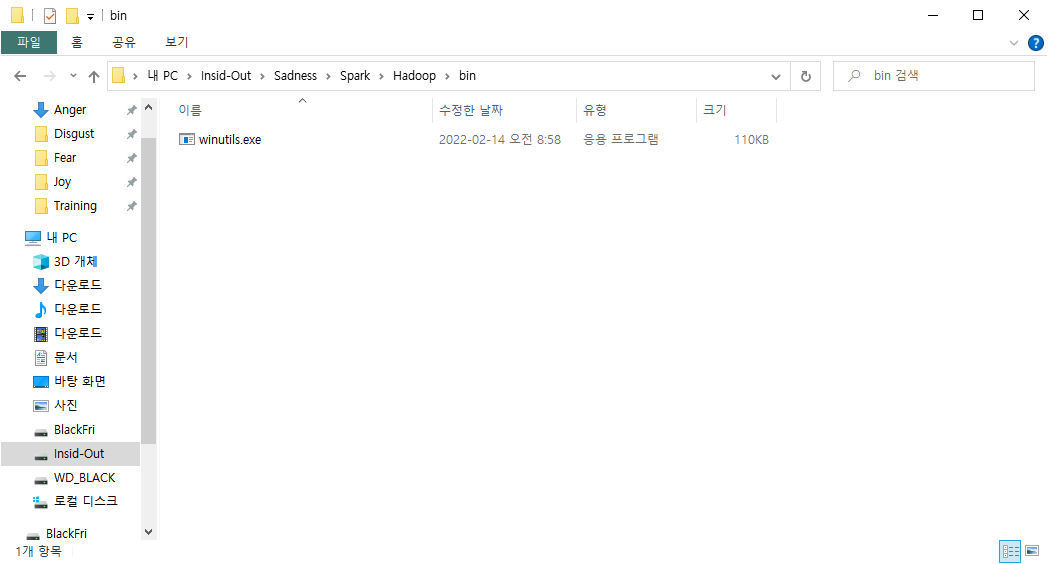
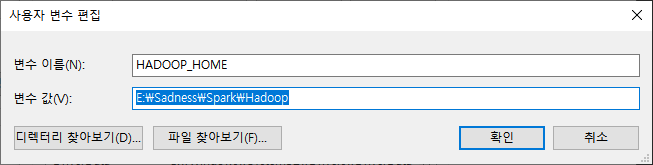
div.noresult-main-title 태그로 인해 server랑 currency 값을 불러올 수 없었다.
URL에서 가져올 수 있겠지만 우선 함수를 빠져나가는 방식으로 업데이트 했다.
1 2 3 4 5 6
defget_data(): ... if (soup.find("div", class_="noresult-main-title").string == "The offer you try to view is no longer available."): driver.close() returnFalse
if return을 추가하니 해당 페이지가 정상 title로 복구됐다… 작동 확인도 못해봤다.
동적 페이지 자동 크롤링을 새벽마다 돌리면서 URL이 변경되지 않는 동작의 경우 요소를 찾을 때 까지 대기하는 코드가 때때로 에러를 일으킨다.
다음에 error가 식별됐을 때 Error 명을 식별해서 try - except 구문으로 예외처리하고 time.sleep 함수를 넣어준 다음 try 재귀 함수를 돌리는 코드를 추가 작성해 업데이트할 예정이다.
try & 재귀함수 추가(20220228)
get_data() 함수에 try - except로 구성된 재귀함수 try_clickable()을 추가했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defget_data():
deftry_clickable(xpath_name): try: i = 0 soup = soup_wait_clickable(xpath_name)
seller.extend(get_data_seller( "a.flex.prechekout-non-produdct-details > div.seller-details.m-l-sm > div.seller__name-detail")) price.extend(get_data_seller( "div.hide > div > div > div > div > div > span.offer-price-amount")) stock.extend(get_data_stock()) except IndexError as e: i += 1 print(e+str(i)) time.sleep(1) soup = try_clickable(xpath_name) return soup
클릭 동작이 들어간 soup_wait_clickable 부분만 업데이트 했지만, 만약 클릭 동작이 필요없는 페이지에서도 IndexError가 발생한다면 앞부분에도 추가해야한다.
getdata[함수] 요소 추가(20220304)
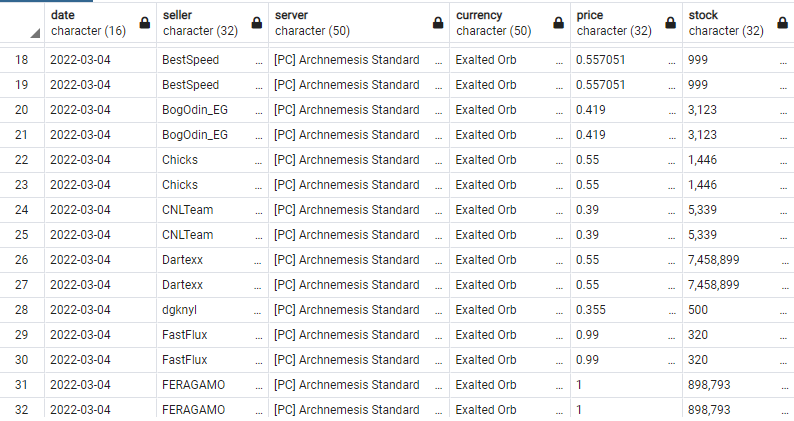
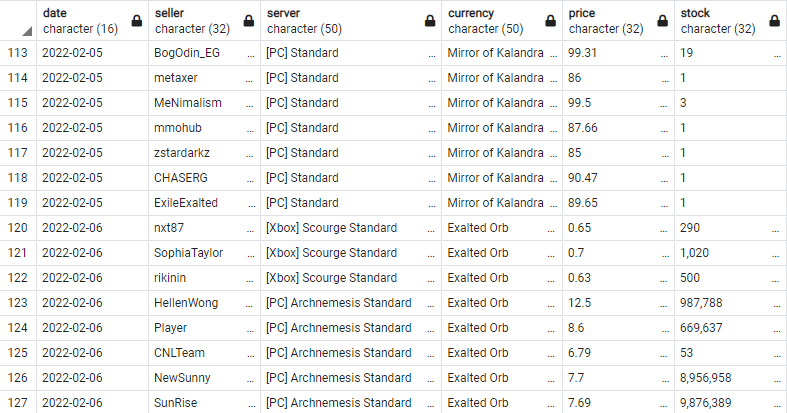
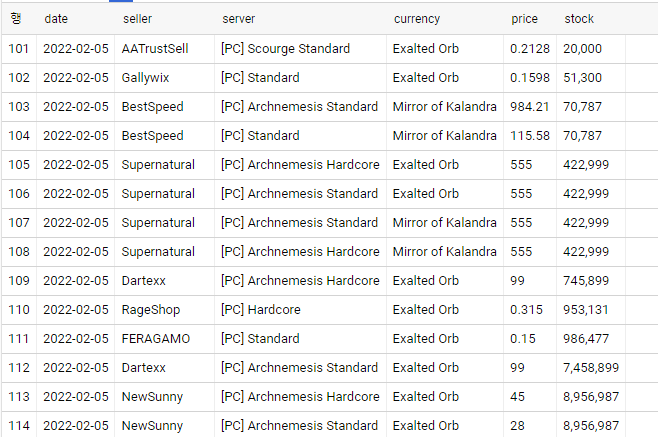
다른 문제로 데이터를 재확인하다가 중복 데이터가 지난 업데이트인 2월 28일부터 들어있음을 확인했다.
처음 문제는 time.sleep() 값이 부족한줄 알고 4까지 넣어봤지만 여전히 중복 데이터가 들어갔다. 아무래도 get_data에서 처리하는 soup 변수가 문제있는거같다. 28일에 백업해둔 코드를 실행해보고 문제가 발생하지 않아 확신했다.
try 함수를 넣으면서 soup의 위치가 get_data.try_clickable()로 들어감.. 기존 soup는 get_data()에 위치했으며, get_data.get_data_seller(selector) or get_data.get_data_stock()에 적용 시 문제 없이 get_data의 soup로 들어갔다.
하지만 이제 내가 넣어야하는 soup는 get_data.try_clickable() 아래에 있는 soup를 넣어야했다.