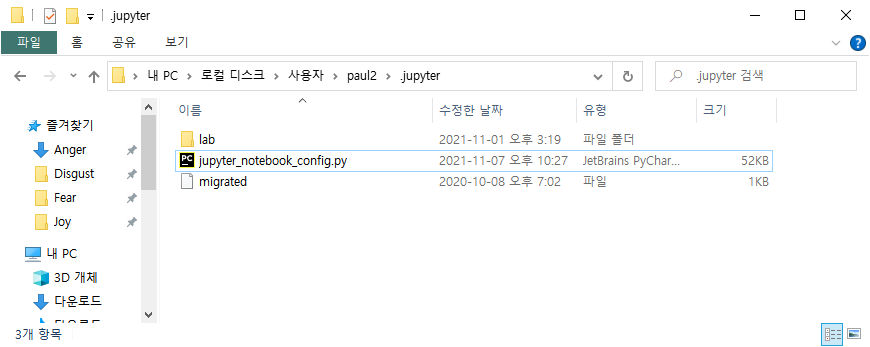
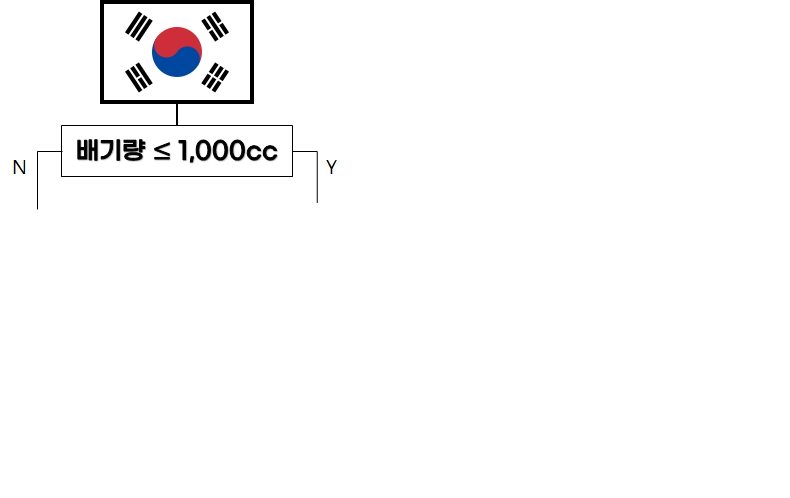
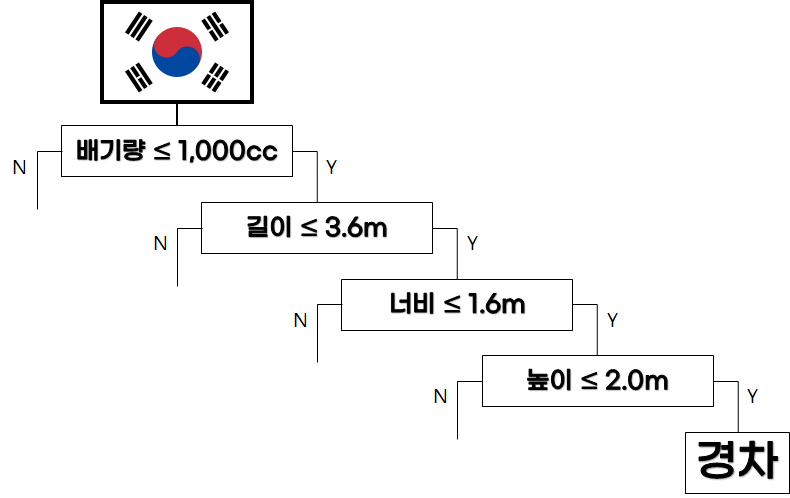
의사결정트리는 여러 객체가 모인 집단에서 절차적 “Yes”||”No” 혹은 간단한 문답문을 이용해 원하는 특성을 가진 객체를 분류해내는 과정이다.
주변에서 한가지 예시를 살펴본다면 법률로 경차를 정의해서 고속도로 / 보험 등 각종 형식으로 혜택을 주는 경우가 있다. 돈과 관련된 문제인 만큼 경차를 분류하는 기준은 필수가 된다.
한국에서의 경차를 보자면
배기량 1,000cc 이하
길이 3.6m 이하
너비 1.6m 이하
높이 2.0m 이하
인 자동차로 정의한다.
그러면 의사결정트리는 어떻게 만들어질까?
우선 나라마다 정의한 경차에 대한 포멧이 다르기 때문에 간단한 문답문을 이용해 어느 나라의 포멧을 불러올지 결정한다.
다음으로 배기량이나 차량의 크기같은 포멧이 만족하는지 하나씩 Y/N 문답을 절차적으로 진행한다. 효율성에 관해선 다음에 설명하고 이번 포스팅에선 배기량부터 순차적으로 진행한다.
위와 같은 의사결정트리(Decision Tree) 과정을 통해 한국의 법률에서 경차로 정의되는 차량을 나눌 수 있다. 객체의 종류가 적다면 큰 문제는 없겠지만, 차량 객체 각각에 대한 데이터를 가지고 있고 법률적인 포멧이 있다면 수 많은 차량에 대한 포멧을 컴퓨터 작업을 통해 간단히 나눌 수 있을 것이다.
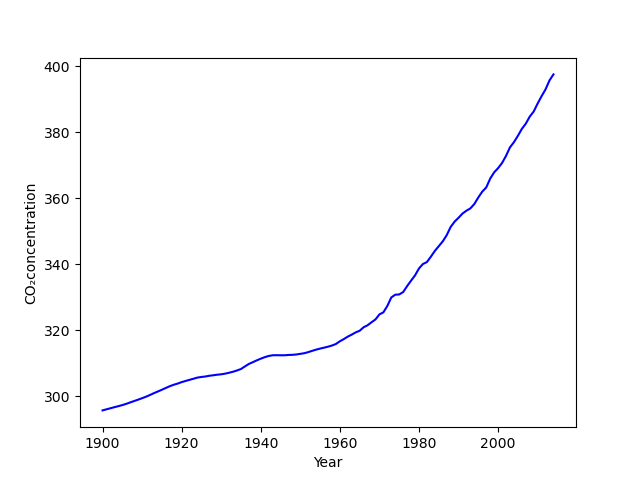
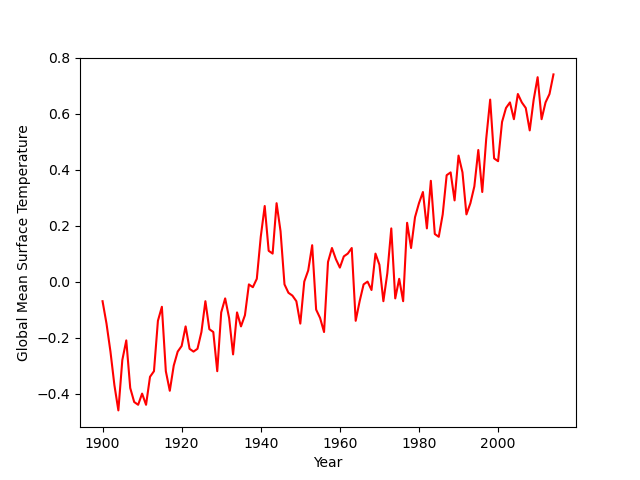
Matplotlib는 matlab 수치해석 프로그램을 python 기반 작업공간에서 다양한 작업을 하기 위해 개발된 외부 라이브러리다. 이 라이브러리에서 그래프를 그리는 방식은 크게 2종류가 있는데, 간편하게 사용할 수 있는 pyplot가 첫번째다. 두번째 방식은 객체지향형 모듈에 좀 복잡한 객체 생성을 거쳐야하지만 다양한 설정 및 한 그래프 공간에 여러 축을 표현할 수 있는 pyplot.subplots가 있다.
data2 = np.genfromtxt(f2, encoding='utf8',dtype=None,delimiter=',',names=('year','value'), skip_header=5) ## 변수 / 인코딩 / 혼합 데이터 : dtype=None / 값 사이 구분 / 열 이름 지정 / 머릿말 생략 열 수
size=len(data2)
print(size)
for i inrange(0,size): t = data2['year'][i] ## year 열의 i번째 값을 t에 저장 if t == 1900: styr = i elif t == 2015: edyr = i i=i+1 print(styr) print(edyr)
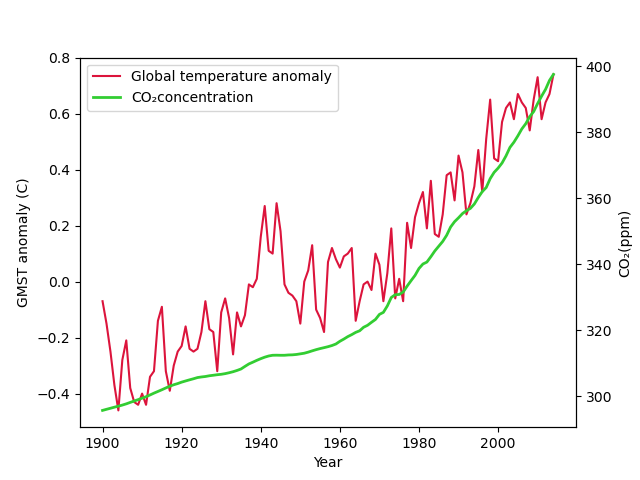
lines = line1 + line2 ## 두 장의 line 그림을 합친 변수 labels = [l.get_label() for l in lines] ax1.legend(lines, labels, loc='upper left') ## loc 'location' ## matplotlin.axes.Axes.legend 참고
plt.show
<IPython.core.display.Javascript object>
<function matplotlib.pyplot.show(block=None)>
1
plt.close()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
fig, ax1 = plt.subplots() ax2 = ax1.twinx()
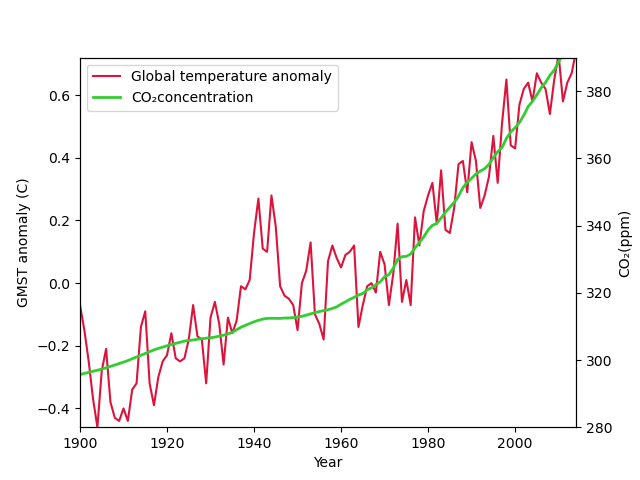
ax1.set_ylabel('GMST anomaly (C)') ax1.set_xlabel('Year') ax2.set_ylabel('CO₂(ppm)') ax1.set_ylim([-0.46,0.72]) ## 범위 조정 ax2.set_ylim([280,390]) ## ax1.set_xlim([1900,2014])
파이썬에서 기본적으로 제공하는 List 형식의 행은 사용할 수 있으나 Math 라이브러리가 추가해주는 method 및 상수는 기본적인 식과 pi 등의 상수 뿐으로 다차원 연산으로 인해 행렬이 필요한 vector나 선형대수 등의 작업 형식에 대해선 복잡해지는 불편함이 있다.
외부 라이브러리 Numpy
위 문제를 해결해주는 라이브러리가 C언어 기반으로 만들어진 Numpy 외부 라이브러리로 작업 공간에서 행렬 형식의 변수를 사용할 수 있게 도와준다.
함수나 변수를 모아 놓은 파이썬 파일 (파일명(.py) = 모듈명 다른 파이썬 프로그램에서 불러와 사용할 수 있게끔 나든 파이썬 파일 여러 모듈을 묶어서 편리하게 관리하기 위해 패키지(디렉토리) 안에 넣어둘 수 있다. 패키지 내부 모듈 안의 특정 함수를 사용하기 위해서는 ‘패키지.모듈명.특정함수명’ 형태로 사용한다. 불러들이는 명령어 : import
r : 읽기 모드 w : 쓰기 모드 a : 추가 모드 (파일의 마지막에 새로운 내용을 추가할 때 사용) , append
1 2 3 4
# open 명령어 : 파일에 작업을 한다.
f = open("새파일.txt", 'w') # w 모드로 파일을 열면 기존 파일의 내용을 전부 지우고 처음부터 작업한다. 추가 입력은 a f.close # 작업 이후 반드시 close로 파일과 연결을 끊어줘야 함
<function TextIOWrapper.close()>
1 2 3 4 5 6 7
# 파일 쓰기 모드로 출력값 입력
f = open("새파일.txt", 'w') for i inrange(1,11): # 1부터 10까지 i에 대입 data = "%d번째 줄입니다. \n" %i #formatted str # \n은 줄바꿈 기호 f.write(data) # data를 파일 객체 f에 입력 f.close()
프로그램 외부에 저장된 파일을 읽는 방법
1 2 3 4 5 6
# readline 함수
f = open("새파일.txt", 'r') line = f.readline() # 파일의 첫 줄을 읽는다. print(line) f.close()
1번째 줄입니다.
1 2 3 4 5 6
f = open("새파일.txt", 'r') whileTrue: line = f.readline() ifnot line: break# line(str) 인 경우 공백이면 fulse , 글자인 경우 true print(line) f.close()
1번째 줄입니다.
2번째 줄입니다.
3번째 줄입니다.
4번째 줄입니다.
5번째 줄입니다.
6번째 줄입니다.
7번째 줄입니다.
8번째 줄입니다.
9번째 줄입니다.
10번째 줄입니다.
1 2 3 4 5 6
f = open("새파일.txt", 'r') lines = f.readlines() f.close() print(lines) for i inrange(1,11): print(lines[i-1])
['1번째 줄입니다. \n', '2번째 줄입니다. \n', '3번째 줄입니다. \n', '4번째 줄입니다. \n', '5번째 줄입니다. \n', '6번째 줄입니다. \n', '7번째 줄입니다. \n', '8번째 줄입니다. \n', '9번째 줄입니다. \n', '10번째 줄입니다. \n']
1번째 줄입니다.
2번째 줄입니다.
3번째 줄입니다.
4번째 줄입니다.
5번째 줄입니다.
6번째 줄입니다.
7번째 줄입니다.
8번째 줄입니다.
9번째 줄입니다.
10번째 줄입니다.
1 2 3 4 5 6
# read 함수 사용하기 f = open("새파일.txt", 'r') data = f.read() print(data) print(type(data)) f.close()
1번째 줄입니다.
2번째 줄입니다.
3번째 줄입니다.
4번째 줄입니다.
5번째 줄입니다.
6번째 줄입니다.
7번째 줄입니다.
8번째 줄입니다.
9번째 줄입니다.
10번째 줄입니다.
<class 'str'>
파일에 새로운 내용 추가하기
1 2 3 4 5
f = open("새파일.txt", 'a') for i inrange(11,20): data = "%d번째 줄입니다. \n" %i f.write(data) f.close()
write문과 함께 사용하기
1 2 3
f = open("foo.txt",'w') f.write("Life is too short") f.close()
1 2 3
# with 문 withopen("foo.txt",'w') as f: f.write("Life is too short") # 자동으로 close 되는 문장
defadd(a,b):## a 와 b는 add라는 함수를 작동시키기 위한 변수 return a+b ## 함수 이름은 ad고 입력으로 2개의 값을 받으며, 결과값은 2개의 입력값을 더한 값이다.
# 메인 프로그램
a=3 b=4 c=add(a,b) print(c)
# Or
result=add(a=3,b=4) print(result)
# Or
result=add(b=3,a=4) ## 변수 이름만 맞추면 변수 순서가 바뀌어도 작동된다. print(result)
7
7
7
1 2 3 4
# 입력값이 없는 함수
defsay(): return'Hi'
1 2
a=say() print(a)
Hi
1 2 3
# retrun(결과값)이 없는 함수 defadd(a,b): print("%d + %d = %d"%(a,b,a+b))
1
add(3,4)
3 + 4 = 7
1 2 3 4 5 6 7 8 9
# 입력값이 몇 개가 될지 모를 때는?
# 여러 개의 입력값을 받는 함수
defadd_many(*arg):# '*' 는 임의의 여러 변수 지정 result=0 for i in arg: result=result+i # *arg에 입력받는 모든 값을 더한다. return result
1 2
result = add_many(1,2,3,4,5) print(result)
15
1 2 3 4 5 6 7 8 9 10 11 12
# 사칙 연산 선택 가능
defadd_mul(choice, *args) : if choice =='add': ## choice 매개변수가 add 일 경우 result = 0 for i in args: result = result+i elif choice =='mul': ## choice 매개변수가 mul 일 경우 result = 1 for i in args: result = result*i return result
1 2 3 4 5
result = add_mul('add',1,2,3,4) print(result)
result2 = add_mul('mul',1,2,3,4) print(result2)
10
24
1 2 3 4 5 6
# 함수의 결과값은 항상 하나 # 함수 결과값은 언제나 하나이기에 오류가 나는 것이 아니라 (7,12)라는 하나의 튜플 값으로 돌려준다. defadd_mul (a,b): return a+b,a*b
result = add_mul(3,4) print(result)
(7, 12)
1 2 3 4 5 6 7 8 9
# 매개변수에 초기값 미리 정하기
defsayself(name,old,man=True):## 초기값 "Ture(or something)" 의 경우 변수 가장 끝에 지정하지 않으면 에러가 발생한다. print("이름 %s" %name) print("나이 %d" %old) if man: print("남성") else: print("여성")
1
sayself("박응",27,True)
이름 박응
나이 27
남성
1
sayself("박선",27,False)
이름 박선
나이 27
여성
1
sayself("박응",27) ## 초기값이 True로 설정되어있다.
이름 박응
나이 27
남성
함수에서 매우 중요한 부분
1 2 3 4 5 6 7 8
# 함수 안에서 선언한 변수의 효력 범위
a = 1# 함수 밖의 변수 a defvartest(a):# 여기서 a는 함수 안에서 a라서 함수 안에서만 작동한다. 함수 밖과는 다른 셀이다. a=a+1 vartest(a) # 여기서 입력값 a는 함수 바깥 a=1을 입력한다는 의미 print(a) # 함수에서 a+1 = 2 가 되었지만 retrun도 없고 함수 안에서의 a만 a=2이 되었다. 메인 셀에서 a는 여전히 1이다.
1
1 2 3 4 5 6 7 8 9
# 함수 안에서 함수 밖의 변수를 변경하는 법
a = 1 defvartest(a): a=a+1 return a # 메인 프로그램 지정변수에 결과값을 돌려준다. a = vartest(a) # 결과값을 지정변수 a에 대입 print(a)
2
1 2 3 4 5 6
# lambda (한줄 함수) 'lambda 매개변수1,매개변수2, ...: 매개변수를 사용한 표현식'