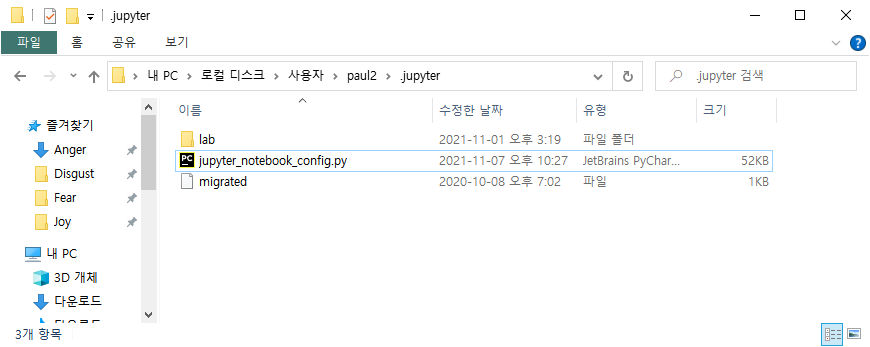
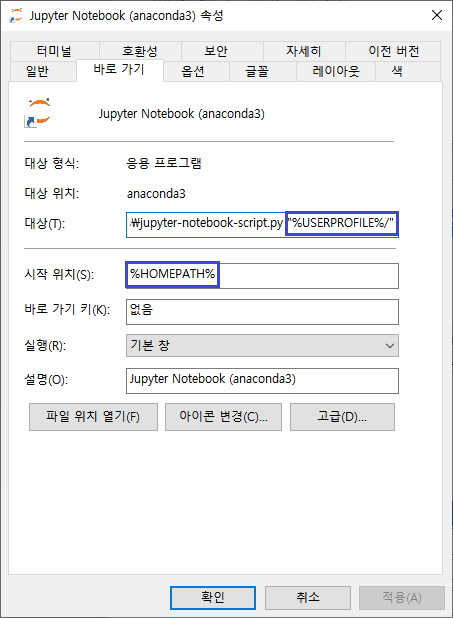
앞으로 많은 그래프를 그려낼거고 df_Jp['Q2'][1:].value_counts() 형식이 반복된다.
df_Jp['Q2'][1:].value_counts()을 객체로 만들어서 넣어도 되겠지만, 이번 작업에서 사용할 df은 df_Jp&df_Ch 2개로 dataframe 객체의 변동이 있고, 칼럼명도 Q1,Q2로 변동이 있다. 위 조건에 부합하는 간단한 함수 하나 만들겠다.
E:\Sadness\anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3165: DtypeWarning: Columns (0,195,201,285,286,287,288,289,290,291,292) have mixed types.Specify dtype option on import or set low_memory=False.
has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
cvs datasat을 불러오는데 위와 같이 DtypeWarning 이라는 경고가 출력되었다.
DtypeWarning 해결하기
filterwarnings
경고 그 자체가 원하는 작업은 아니지만 문제가 발생하지 않는 이상 user는 경고를 무시해도 상관없다.
권장하지 않지만 거슬린다면 warnings 모듈의 경고 필터 ignore를 사용해 경고 출력을 무시할 수 있다.
1 2
from warnings import filterwarnings filterwarnings('ignore')
low_memory
하지만 근본적인 해결은 아니므로 terminal이 제안한 방식인 low_memory=False 를 넣어 해결할 수 있다.
1
df = pd.read_csv("csv url", low_memory=False)
위 방식은 각 column마다 data type을 추측하는 방식으로 옵션명(낮은 메모리)처럼 작업량이 data 크기에 비례해 증가한다.
방대한 데이터를 처리해야되서 Dtype 추측 방식이 부담된다면?
dtype 형식 지정
불러올 file의 문자 형식을 알고 있다면 dtype을 지정해 warning을 해결하고 memory 가용량도 줄일 수 있다.
definput_num(): print("input Question no.: ") Qnum = input() Qnum_subQ = [s for s in df_col_name if"Q"+Qnum+"_"in s] if Qnum_subQ == []: return"Q"+Qnum+" has not part_Q" Question_type = None if [s for s in Qnum_subQ if ("A"or"B") in s]: print("input Q"+Qnum+"'s type") Question_type = input().upper() if Qnum_subQ: print("input Q"+Qnum+"'s last part no.: ") part_num = input() return questions_count(Qnum,part_num,Question_type)
위 함수는 Question number(Qnum)을 입력받은 뒤 이전에 정의한 칼럼명을 추출해 낸 df_col_name 객체내에서 "Q"+Qnum+"_" 문자열이 있는 sub_Question 형식을 찾아낸다.
Data Transformation에서 얻어낸 코드는 Qnum 만 있는 경우에 대한 작업이 없으므로 이 경우는 line6 조건문에서 함수를 종료한다.
line 9의 if문에선 'A' or 'B' 문자가 들어있는 문자열을 list에서 식별해 해당하는 경우엔 Question_type 객체에 type을 입력 받게 되는 조건문을 작성했다. 이 때, upper() 함수를 이용해 소문자로 입력받아도 대문자로 자동변환되게 설정했다.
line 14의 조건문은 sub Question의 마지막 열을 입력받는 조건문으로 사용자가 ‘kaggle_survey’에서 직접 확인해서 input 값을 정해야한다.
Matplotlib는 matlab 수치해석 프로그램을 python 기반 작업공간에서 다양한 작업을 하기 위해 개발된 외부 라이브러리다. 이 라이브러리에서 그래프를 그리는 방식은 크게 2종류가 있는데, 간편하게 사용할 수 있는 pyplot가 첫번째다. 두번째 방식은 객체지향형 모듈에 좀 복잡한 객체 생성을 거쳐야하지만 다양한 설정 및 한 그래프 공간에 여러 축을 표현할 수 있는 pyplot.subplots가 있다.
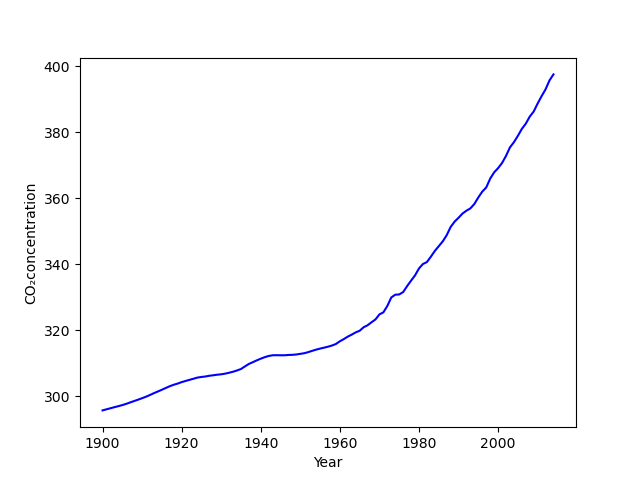
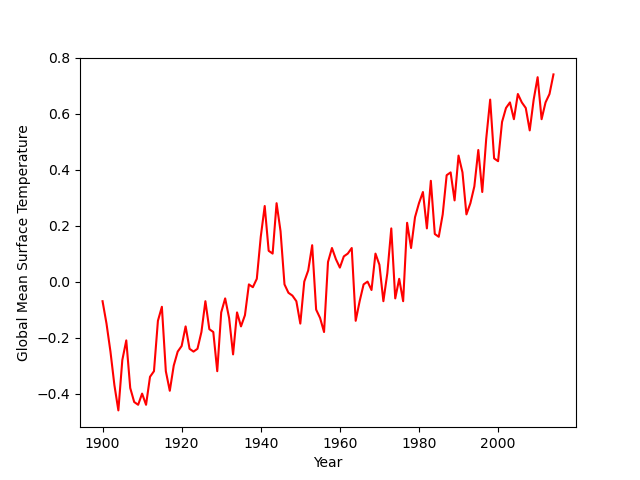
data2 = np.genfromtxt(f2, encoding='utf8',dtype=None,delimiter=',',names=('year','value'), skip_header=5) ## 변수 / 인코딩 / 혼합 데이터 : dtype=None / 값 사이 구분 / 열 이름 지정 / 머릿말 생략 열 수
size=len(data2)
print(size)
for i inrange(0,size): t = data2['year'][i] ## year 열의 i번째 값을 t에 저장 if t == 1900: styr = i elif t == 2015: edyr = i i=i+1 print(styr) print(edyr)
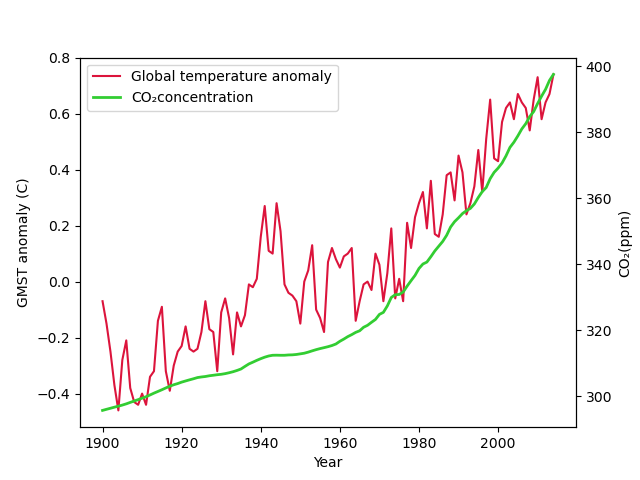
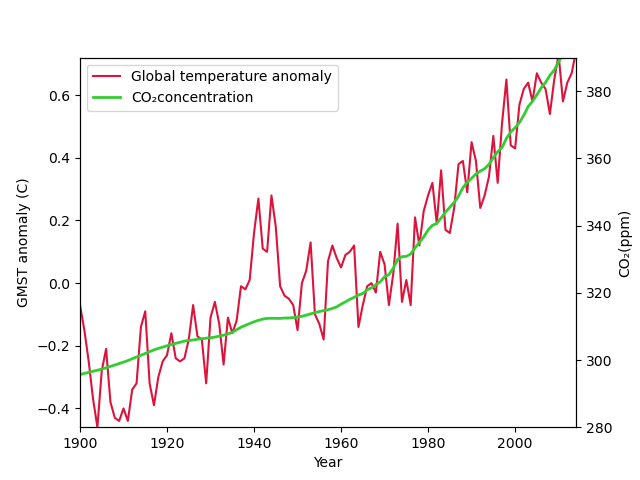
lines = line1 + line2 ## 두 장의 line 그림을 합친 변수 labels = [l.get_label() for l in lines] ax1.legend(lines, labels, loc='upper left') ## loc 'location' ## matplotlin.axes.Axes.legend 참고
plt.show
<IPython.core.display.Javascript object>
<function matplotlib.pyplot.show(block=None)>
1
plt.close()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
fig, ax1 = plt.subplots() ax2 = ax1.twinx()
ax1.set_ylabel('GMST anomaly (C)') ax1.set_xlabel('Year') ax2.set_ylabel('CO₂(ppm)') ax1.set_ylim([-0.46,0.72]) ## 범위 조정 ax2.set_ylim([280,390]) ## ax1.set_xlim([1900,2014])
파이썬에서 기본적으로 제공하는 List 형식의 행은 사용할 수 있으나 Math 라이브러리가 추가해주는 method 및 상수는 기본적인 식과 pi 등의 상수 뿐으로 다차원 연산으로 인해 행렬이 필요한 vector나 선형대수 등의 작업 형식에 대해선 복잡해지는 불편함이 있다.
외부 라이브러리 Numpy
위 문제를 해결해주는 라이브러리가 C언어 기반으로 만들어진 Numpy 외부 라이브러리로 작업 공간에서 행렬 형식의 변수를 사용할 수 있게 도와준다.
함수나 변수를 모아 놓은 파이썬 파일 (파일명(.py) = 모듈명 다른 파이썬 프로그램에서 불러와 사용할 수 있게끔 나든 파이썬 파일 여러 모듈을 묶어서 편리하게 관리하기 위해 패키지(디렉토리) 안에 넣어둘 수 있다. 패키지 내부 모듈 안의 특정 함수를 사용하기 위해서는 ‘패키지.모듈명.특정함수명’ 형태로 사용한다. 불러들이는 명령어 : import