g2g-crawling04: 동적페이지 로드 문제 발생
동적 페이지 자동 크롤링을 새벽마다 돌리면서 URL이 변경되지 않는 동작의 경우 요소를 찾을 때 까지 대기하는 코드가 때때로 에러를 일으킨다.
다음에 error가 식별됐을 때 Error 명을 식별해서 try - except 구문으로 예외처리하고 time.sleep 함수를 넣어준 다음 try 재귀 함수를 돌리는 코드를 추가 작성해 업데이트할 예정이다.
try & 재귀함수 추가(20220228)
get_data() 함수에 try - except로 구성된 재귀함수 try_clickable()을 추가했다.
1 | def get_data(): |
클릭 동작이 들어간 soup_wait_clickable 부분만 업데이트 했지만, 만약 클릭 동작이 필요없는 페이지에서도 IndexError가 발생한다면 앞부분에도 추가해야한다.
getdata[함수] 요소 추가(20220304)
다른 문제로 데이터를 재확인하다가 중복 데이터가 지난 업데이트인 2월 28일부터 들어있음을 확인했다.
1 | SELECT * FROM poe where date = '2022-03-04' order by currency, server, seller; |
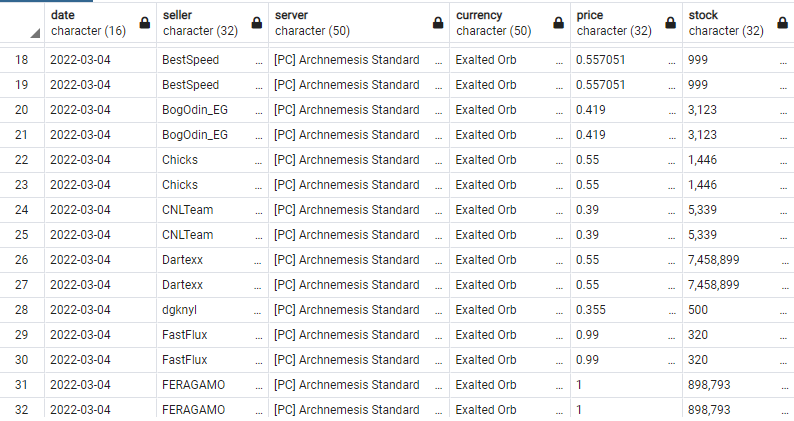
일단 당장 새로 갈아끼울 수 있는 3/4 데이터만이라도 삭제한다
1 | --PostgreSQL |
ㅈ됨. 나중에 데이터를 쓸 때 2/27이나 3/4 데이터를 사용해서 어떻게든 처리해야겠지
처음 문제는 time.sleep() 값이 부족한줄 알고 4까지 넣어봤지만 여전히 중복 데이터가 들어갔다.
아무래도 get_data에서 처리하는 soup 변수가 문제있는거같다.
28일에 백업해둔 코드를 실행해보고 문제가 발생하지 않아 확신했다.
try 함수를 넣으면서 soup의 위치가 get_data.try_clickable()로 들어감..
기존 soup는 get_data()에 위치했으며, get_data.get_data_seller(selector) or get_data.get_data_stock()에 적용 시 문제 없이 get_data의 soup로 들어갔다.
하지만 이제 내가 넣어야하는 soup는 get_data.try_clickable() 아래에 있는 soup를 넣어야했다.
따라서 getdata 함수를 아래와 같이 요소를 추가했다.
1 | def get_data(): |
마찬가지로 getdata 함수를 사용하는 구문에도 soup 요소를 추가했다.
2022-02-28 ~ 2022-03-03 오또케…
외부링크
g2g-crawling04: 동적페이지 로드 문제 발생
https://hangack.github.io/2022/02/24/Codding/Python/crawling_G2G/g2g-crawling04/