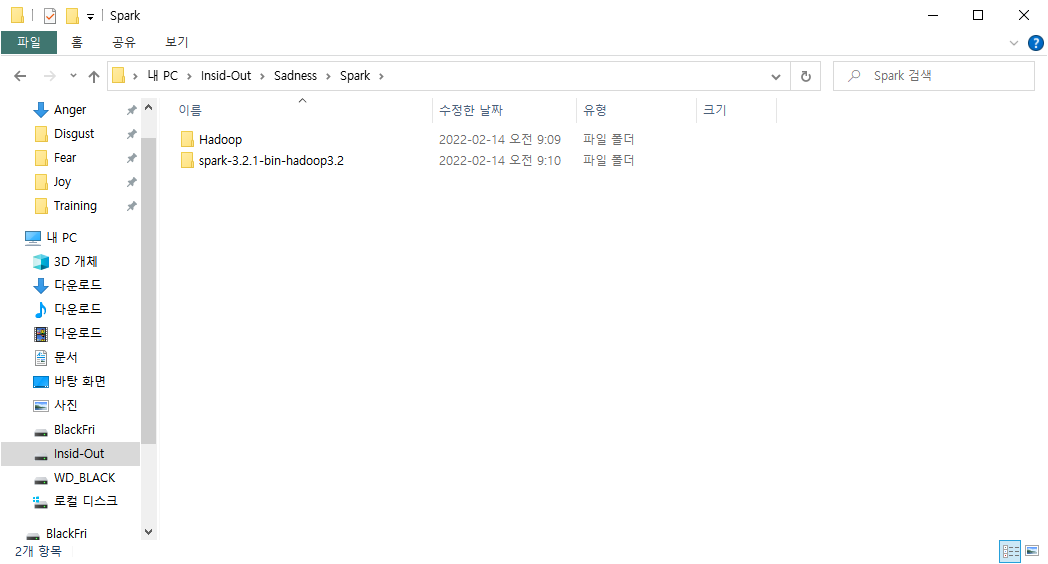
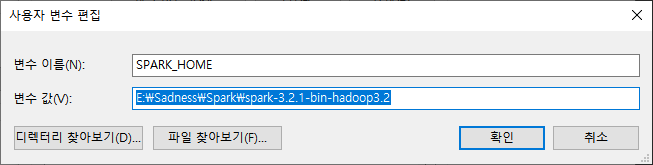
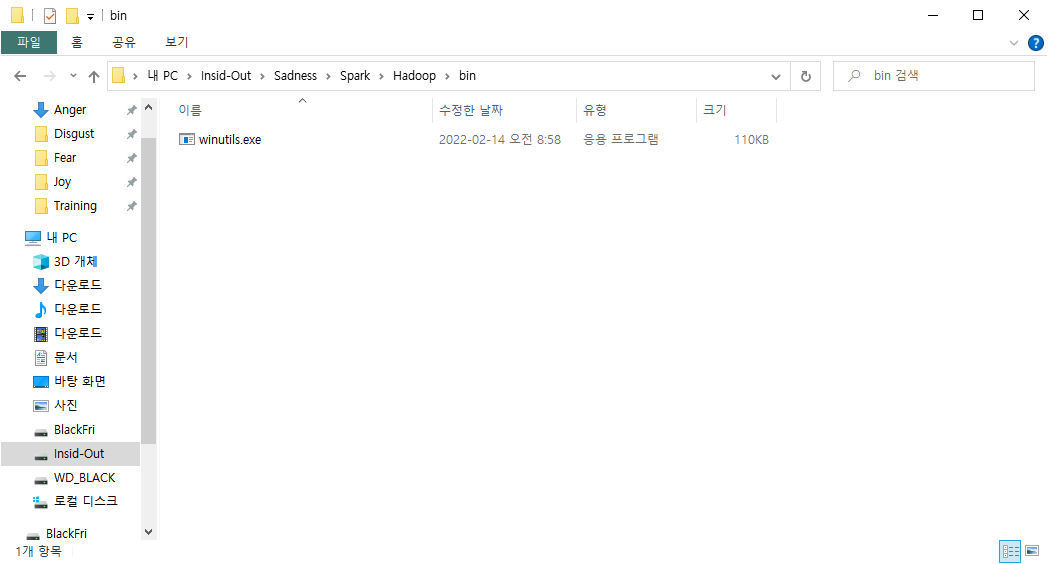
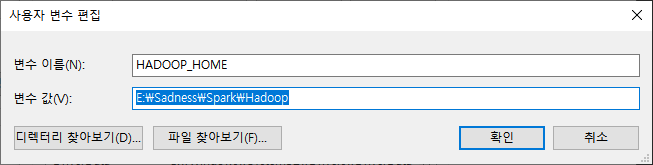
Steam Next Fest
개발중 혹은 출시예정 게임의 데모버전을 1주간 플레이 가능한 스팀 행사: NEXT FESTIVAL의 2022년 2월 버전

많은 유저의 플레이 후기를 듣고 구매하기엔 힘든 인디게임 특성상 플레이어가 30분이 됐건 반나절이 넘던 부담없이 플레이하고 찜해놓을 수 있다는 장점이 크다.
플레이
아직 많은 게임을 해보지는 않았다.
Godlike_Burger
코옵 게임인 overcooked!와 비슷하게 레스토랑 디펜스 형식을 사용한 <Godlike_Burger>

타이쿤류 모바일 게임같은 인터페이스와 대비되어 스토리 배경과 소재가 굉장히 어둡다. Pegi-18로 분류되지 않을까 싶다.
로그라이크, 디펜스, PvE, 경영, 함정을 이용한 전략 시뮬 등 다양한 장르를 녹여놨다.
4시간 이전에 그만둔 이유는 스테이지간 레벨 간격이 너무 넓었다. 첫 행성에서 신경써야하는 손놈은 한 종족밖에 없었으나,
플레이가 너무 지루해 두번째 생성으로 넘어가고 종족이 4종류가 되고, 극단적으로 늘어난 종족과 높은 종족 능력치가 부족한 정보력과 자원의 빈공간을 강하게 파고들었다.
게다가 대응해야할 손놈이 1에서 4로 늘고 레시피도 복잡해지면서 플레이어는 갑작스레 뇌지컬 요구를 강하게 받았고 화면 사방에 조그맣게 보이는 손놈 아이콘을 통해 자원 유통해야 했지만 4종족이나 되는 복잡성에 강한 스트레스도 주어졌다.
그렇다고 첫 행성으로 돌아가기엔 1종족 상대는 또 극단적인 자동화로 게임플레이가 극단적으로 지루해진다.
데모버전이라 많은걸 넣지 못하고 초반/중반/중후반의 세 스테이지만 넣은거같지만 초반-중반 과정의 난이도차가 너무 심하기에 적당한 데모 플레이를 위한 초중반 스테이지 추가가 필요하다 생각한다.
IXION
그리스 신화: 죄를 지어 수레바퀴에 걸린 인간의 이름을 따온 IXION
사운드가 안나와서 가오갤 이후 오랜만에 그래픽드라이버 업데이트를…
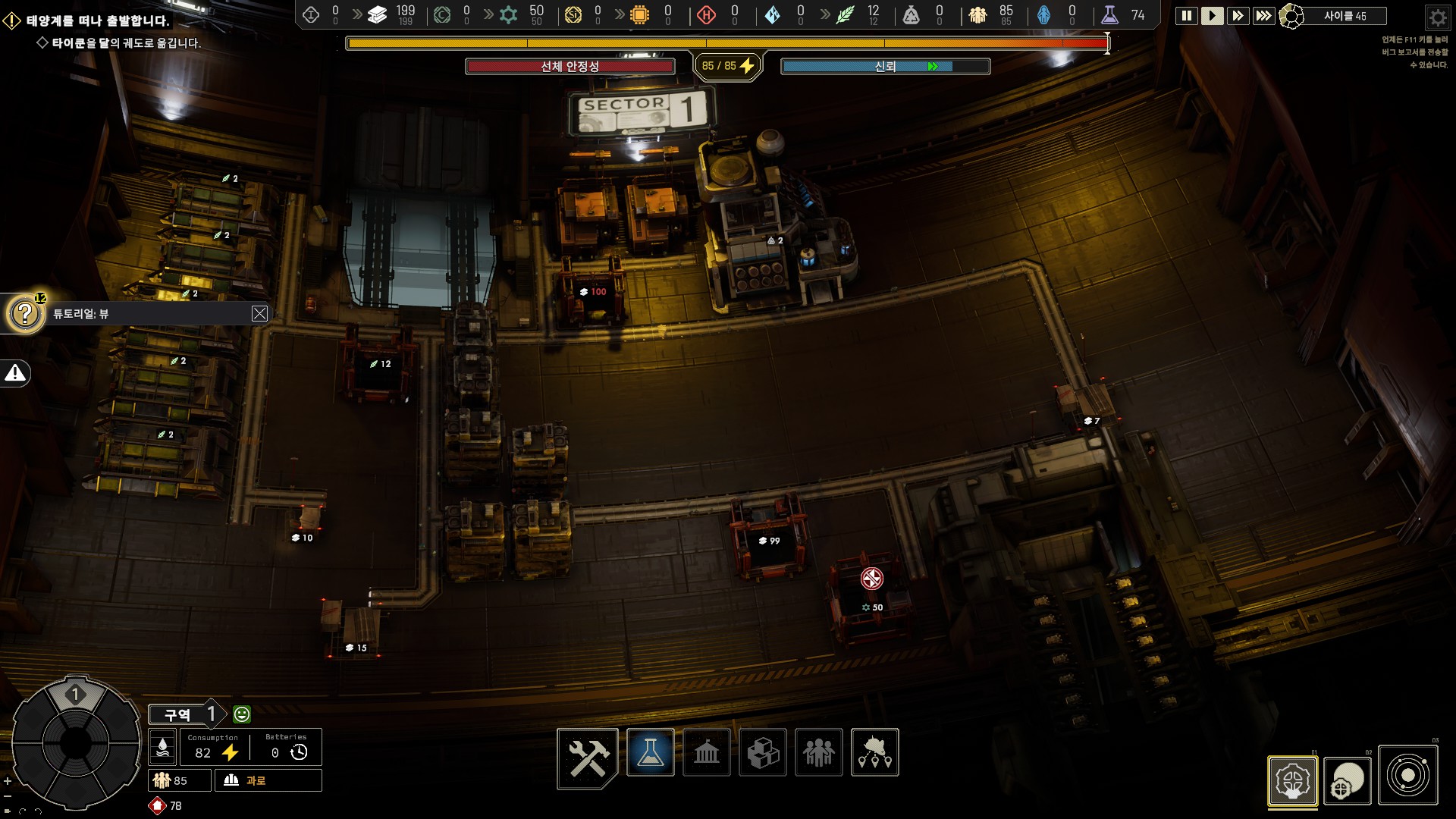
우주 배경의 타이쿤이라는 모선에서 이뤄지는 도시 경영 시뮬레이션.
공개된 내용은 다른 은하로 발진하기까지 과정이 끝이다.
플레이하면서 <프로스트 펑크>와 유사한 인상을 받았고 <파피용> 소설로부터 영감을 받은 작품으로 느껴졌다.
데모 플레이는 아포칼립스 배경(혹은 도시경영)의 시뮬레이션에 익숙한 유저에 대한 데이터 수집이 목적인 구성으로 느껴졌다.
한글의 문제인진 모르겠지만 목표 등을 나타내는 인터페이스가 잘 들어오지 않아 사이클 낭비로 식량 부족 문제가 발생해 리트라이했다.
외부링크